Problem
If you use Solr for any technical corpus, you will soon need to know how to perform indexing special terms using Solr. Solr supplies some really convenient field types in their default schema.xml. If you have used text-general to index any
document with special terms (words) you have probably experienced the frustration with missing hyphenated terms. Also, special terms like computer skills are not indexed correctly.
Requirement
Index documents like resumes and job descriptions, which contain terms that include punctuation. Preserve the punctuation on terms that need to be indexed, but remove similar punctuation else where so other terms are also properly indexed.
Solution
Before we look at the solution, let's consider how Solr's fieldType element works. As you would expect, I am going to point you to the official Solr Wiki on Analyzers, Tokenizers and TokenFilters. Although you can put your tokenizers, filters and charFilter elements in any order you choose, Solr will process them in this order.
- charFilter
- analyzer
- filter
text_general Breakdown
Let us break down the out-of-the-box text_general fieldType as copied from the default schema.xml that ships with Solr 4.0.
<!-- A general text field that has reasonable, generic
cross-language defaults: it tokenizes with StandardTokenizer,
removes stop words from case-insensitive "stopwords.txt"
(empty by default), and down cases. At query time only, it
also applies synonyms. -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
Index Analyzer
The Index Analyzer defines the path of parsing data to index it. This happens when the document is added to the Solr core. This is the breakdown of how the indexing is performed for text_general.
- The solr.StandardTokenizerFactory is used to tokenize (aka break apart) the text into individual elements (tokens).
- The solr.StopFilterFactory reads the file stopwords.txt, and removes any tokens that exists in the stopwords.txt file.
- The solr.LowerCaseFilterFactory simply converts all the tokens to lower case, as the name implies.
Query analyzer
- The solr.StandardTokenizerFactory is used to tokenize (aka break apart) the text into individual elements (tokens).
- The solr.StopFilterFactory reads the file stopwords.txt, and removes any tokens that exists in the stopwords.txt file.
- The solr.SynonymFilterFactory reads the file synonyms.txt and expands or replaces matched tokens.
- The solr.LowerCaseFilterFactory simply converts all the tokens to lower case, as the name implies.
Effects on Index
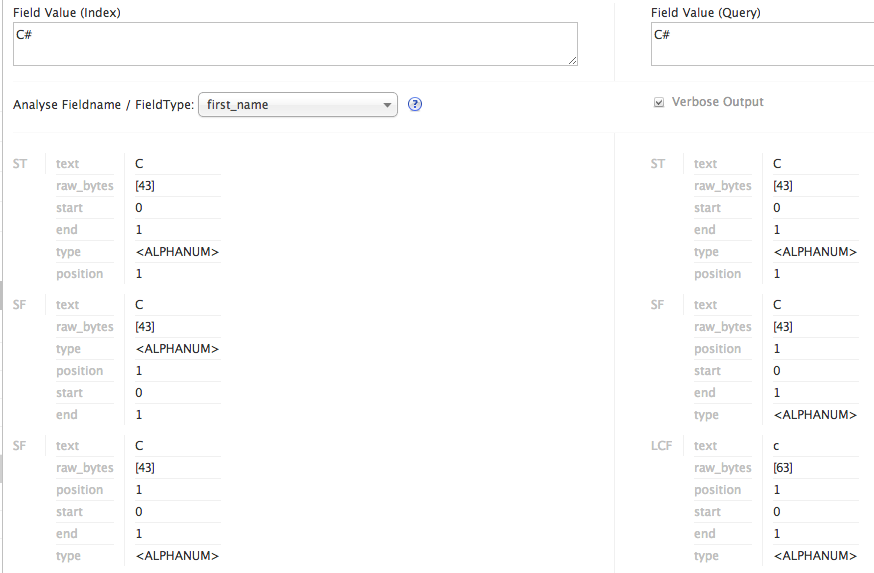
Figure 1
The reason why this default field type wreaks havoc on our special terms, is because the StandardTokenizerFactory splits (tokenizes) on whitespace and punctuation. Lets go ahead and call out some specific terms and focus on the effects of
these
analyzers.
C++ and C#
When you need to know how Solr is parsing terms for indexing and querying, you should use the "Analyzer" feature under the individual cores. In this figure, you can see how a field that is text_general reduces the term C# to just "c". Those
of
you know know your "C's" can attest that C, C++ and C# are not the same thing, and you would not want the three treated the same while searching.
text_tech breakdown
Now we are going to create a new fieldType called text_tech. This will be a fieldType that is more friendly with technical terms, and good at parsing documents with terms like Oracle 8i/9i/10g/11g and DB2/UDB.
<fieldType name="text_tech" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(\.\s)" replacement=" " />
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(\.$)" replacement="" />
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(,)" replacement=" " />
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(;)" replacement=" " />
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(\|)" replacement=" " />
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="(\/)" replacement=" " />
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="punctuation-whitelist.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="punctuation-whitelist.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Contents of punctuation-whitelist.txt
c++ => cplusplus
C# => csharp
.NET => dotnet
Index Analyzer
The Index Analyzer defines the path of parsing data to index it. This happens when the document is added to the Solr core. This is the breakdown of how the indexing is performed for text_tech.
- The series of charFilter PatternReplaceCharFilterFactory lines take common punctuation patterns that we know are not patterns
- (\.\s) matches end of sentences where there is a period followed by a space.
- (\.$) matches end of sentences where there is a period followed by the end of a line.
- (,) matches any comma. This is typically used to separate skills in a skill listing.
- (;) matches semi-colons.
- (\|) matches a vertical pipe.
- (\/) matches a front slash.
- The solr.WhiteSpaceTokenizerFactory is used to tokenize (aka break apart) the text into individual elements (tokens). This only breaks on white space leaving all punctuation intact.
- The solr.SynonymFilterFactory reads the file punctuation-whitelist.txt and expands or replaces matched tokens.
- The solr.StopFilterFactory reads the file stopwords.txt, and removes any tokens that exists in the stopwords.txt file.
- The solr.LowerCaseFilterFactory simply converts all the tokens to lower case, as the name implies.
Query analyzer
- The solr.WhiteSpaceTokenizerFactory is used to tokenize (aka break apart) the text into individual elements (tokens). This only breaks on white space leaving all punctuation intact.
- The solr.SynonymFilterFactory reads the file punctuation-whitelist.txt and expands or replaces matched tokens.
- The solr.StopFilterFactory reads the file stopwords.txt, and removes any tokens that exists in the stopwords.txt file.
- The solr.LowerCaseFilterFactory simply converts all the tokens to lower case, as the name implies.
Effects on Index
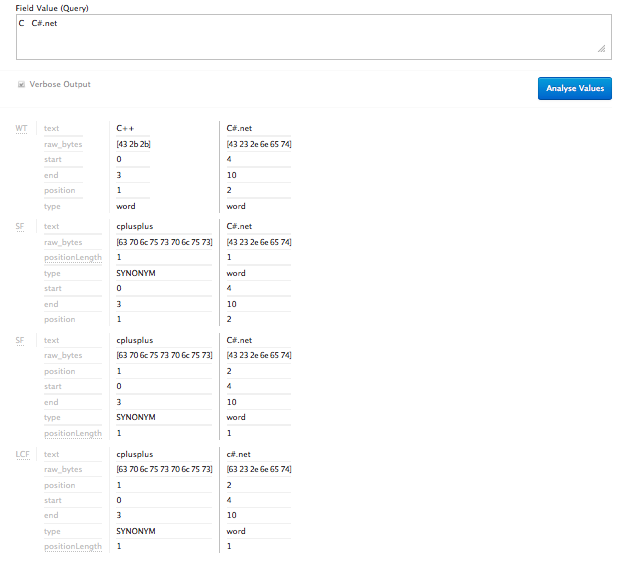
Figure 2
The reason why the index and query parser now respect the special characters is attributed mostly to the use of the WhiteSpaceTokenizerFactory since it does not strip out all of the punctuation during the tokenization process.
Since there is not a perfect tokenizer for knowing which punctuation we do and do not want to keep, we help is a little but using the charFilter. We take common punctuation that is not commonly associated with technical terms, and just convert
it to whitespace so the tokenizer can do all the heavy lifting. As you can see, using regular expressions goes a long way. Knowing regular expressions is a must if you are to succeed in the world of big data and large text processing.
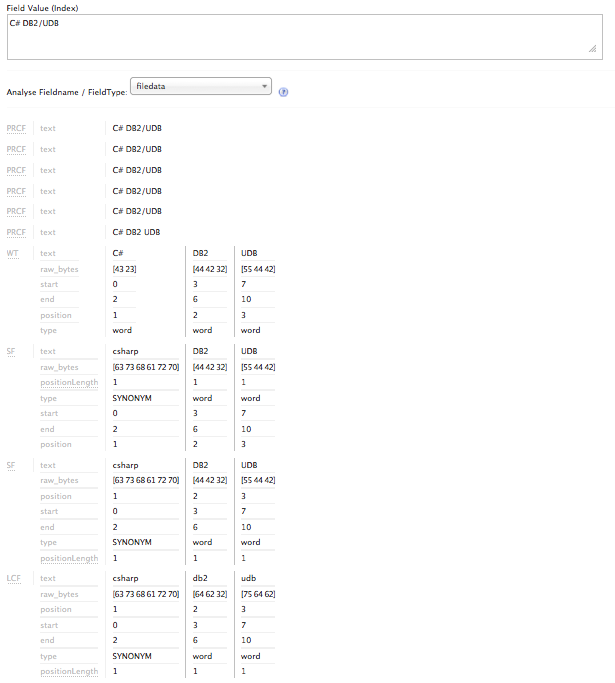
Figure 3
So C# gets conveniently converted to csharp thanks to puncutation-whitelist.txt and the SynonymFilterFactory. You should know that the synonyms are converted for the process of indexing and querying only. A search in Solr for C# with
highlighting enabled accurately highlights the searched and matched term, "C#" in this case, even though our token was converted to "csharp" during indexing and our query term was converted to "csharp" for the actual query.
Conclusion
The ability to define you own fieldTypes in Solr is a very powerful feature. The use of charFilter, tokenizer and filter allow you to slice and dice your text anyway you see fit. Using regular expressions along with the built in Solr filters
should allow you to tackle just about any use case you come across.
Solr is a great Lucene wrapper that allows the developer to focus on the system and product being developed, while exerting less energy on the search engine. Is a Solr Implementation easy? It is not. But, it is easier than trying to build
your
own search algorithms. And, it is really fast once you get it dialed in.
